About That "Dramatic Growth of Swearing in Books"
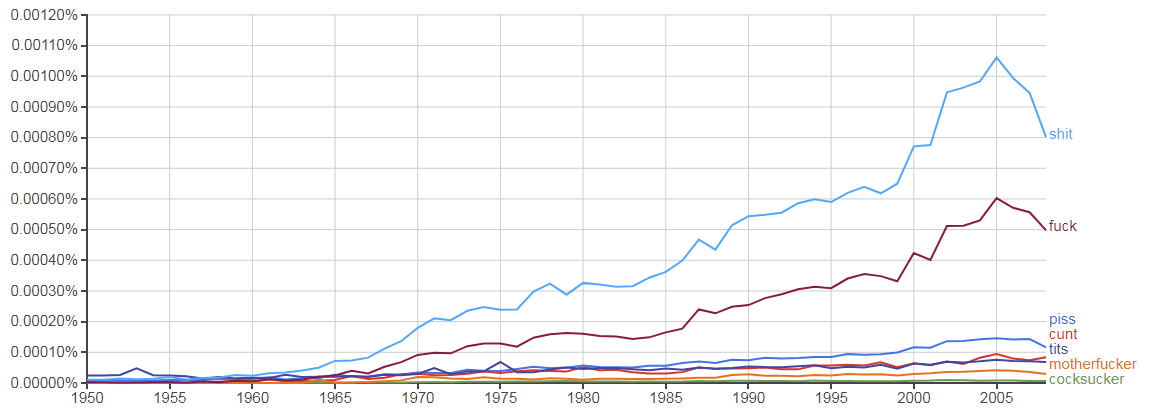
A recently published academic paper has shown that the weakening of censorship inside publishers has lead to a dramatic increase in the use of swear words in American books since 1950.
The paper itself is available as a free download, which is how we know The Guardian’s summary is pretty good:
Mark Twain wrote: “There ought to be a room in every house to swear in,” because “it’s dangerous to have to repress an emotion like that”. Today, the great American novelist might have applauded the increase in cursing, with a new study identifying a “dramatic” increase in swear words in American literature over the last 60 years.
Sifting through text from almost 1m books, the study found that “motherfucker” was used 678 times more often in the mid-2000s than the early 1950s, occurrences of “shit” multiplied 69 times, and “fuck” was 168 times more frequent.
Led by Jean Twenge, author and psychology professor at San Diego State University, the team analysed the titles making up the Google Books corpus of American English books published between 1950 and 2008, looking for uses of the words “shit”, “piss”, “fuck”, “cunt”, “cocksucker”, “motherfucker”, and “tits”. They picked these words because they were described as the “seven words you can never say on television” by comedian George Carlin in 1972.
Overall, they found that writers were “significantly more likely to use each of the seven swearwords in the years since 1950”, with books published in 2005-2008 28 times more likely to include swearwords than books published in the early 1950s.
“I had guessed that the use of swearwords would increase, but I was surprised that the increase was so large – 28 times more,” Twenge said.
What caught my eye about this story was that the data came from Google Ngram Viewer and is publicly available. This means we get to play with it, too.
I’ve been exploring the data this morning, and I found an interesting quirk in the source data set.
Google has two different data sets for Google Ngram Viewer. (Actually, there’s ten or so but most of the data sets can be divided into one of two groups.) One is based on scans of books digitized in 2009, and the other is based on scans digitized in 2012. According to Google, the latter year had "more books, improved OCR, improved library and publisher metadata."
Depending on which data set you choose, you will either see an increase (2009) or decrease (2012) in the use of swear words since 2005.
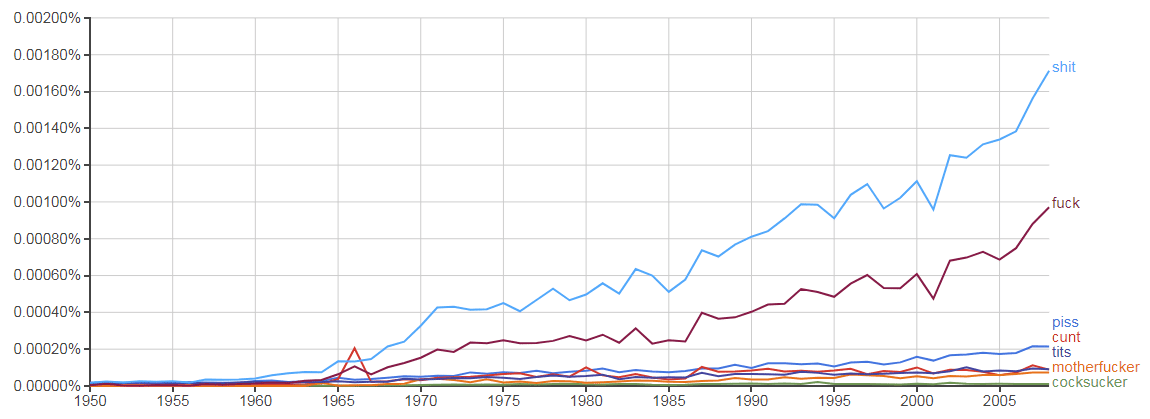
I found this on my own, but the researchers were also aware of the discrepancies. They wrote it off in a footnote because they "could not determine whether this downturn was due to an error in this database or to some other cause".
I don’t know about you but I thought Google’s explanation of "more books" explained the differences well enough.
The 2009 data set was likely missing books affected by the Google Books lawsuit, while the 2012 data set could have included titles which Google was selling in Google Play Books or books that publishers uploaded to Google Books during one of the period where that lawsuit was almost settled.
Either way, the more complete data set paints a very different picture.

Comments
Jan August 14, 2017 um 3:54 pm
This is a big reason why I mostly read Project Gutenberg books.
MikeOh Shark August 14, 2017 um 6:16 pm
Fortunately, I read mostly non-fiction. Technical books are mostly clean.
nameno August 15, 2017 um 2:07 am
Good rule: If you want to read fiction, pick a book that is at least 200 years old.
S. J. Pajonas August 25, 2017 um 5:31 pm
Lol. I love how the comments here are leaning towards no-swearing is better. I love that books contain swearing now because it feels more true to life. But I’m not offended by swearing at all.
Cuss words | Making Book November 14, 2017 um 10:55 am
[…] The Digital Reader brings a report of an academic study of the issue. He points out problems in the data which can be interpreted to show a decrease in swear words since 2005 — however I suspect that year-to-year fluctuations are pretty irrelevant. Just as back before the mid-twentieth century you’d take your hero and heroine up to the bedroom and then discretely close the door, you’d surely not have them damning and blasting — well that you might, but they’d never utter the stronger versions of cuss words which are omnipresent nowadays. Edwin Battistella tells us in Bad Language that the f-word appears over 4,000 times in James Kelman’s How Late It Was, How Late. (That’s averaging over nine per demy octavo page.) And I’d maintain that every one of them was justified — that’s just how (many) Scots (and of course non-Scots) speak and think! […]